小模型,大作用:让你的大语言模型如虎添翼的“插件”秘诀
你可能觉得,像 GPT-4 这样的大语言模型(LLM)已经无所不能了,从写代码到聊哲学,样样精通。但实际上,这位“全能学霸”也有自己的烦恼。而一个巧妙的解决方案,正在变得越来越流行:给它装上一些小巧精悍的“插件”——也就是小模型。
这篇文章,我们就用大白话聊聊,为什么强大的 LLM 需要小模型来帮忙,以及它们是如何强强联手的。
1. “全能学霸”与“特长生”
让我们先建立一个简单的认知。我们可以将大语言模型(LLM)想象成一位知识渊博的“通才教授”,他读过海量的书籍,天文地理、古今中外无所不晓,像 GPT 系列、LLaMA 3、国产的 Deepseek 都属于这一类,优势是知识面广,能理解复杂的逻辑和对话。相比之下,小模型就像一位“特长生”,他可能只专注于一个非常窄的领域,比如“识别法律合同里的风险条款”或者“诊断特定的植物病害”。虽然他的知识面窄,但在自己的专业领域里,他比“通才教授”懂得更深、反应更快。过去,我们认为这两者是不同场景下的选择题,但现在,我们发现它们更是可以协同作战的黄金搭档。
2. “通才教授”的烦恼
为什么 LLM 这位“通才教授”需要“特长生”的帮助呢?主要有三个现实问题。首先是其核心大脑不开放(模型权重访问受限),像 GPT-4 这样的顶级模型,其核心的“思考模式”(即模型权重)是保密的,我们只能调用它的 API,没法对它的“大脑”进行微调,让它在某个特定领域变得更专业,就像你不能改变教授的思维方式一样。其次是运行成本太高昂,LLM 的“大脑”极其复杂,参数量动辄上千亿,这意味着运行它需要非常强大的服务器(比如昂贵的 GPU 集群),这对于大部分个人开发者或小公司来说,是一笔巨大的开销。最后,它的“临时记忆”也有限,我们可以通过提示词(Prompt)给 LLM 一些临时信息,这叫“上下文学习”,就好比在考试前递给教授几张写满要点的小纸条,但这个“小纸条”的容量是有限的,如果你想让他记住一整本专业教材再去回答问题,他可能看到后面就忘了前面,效果会大打折扣。
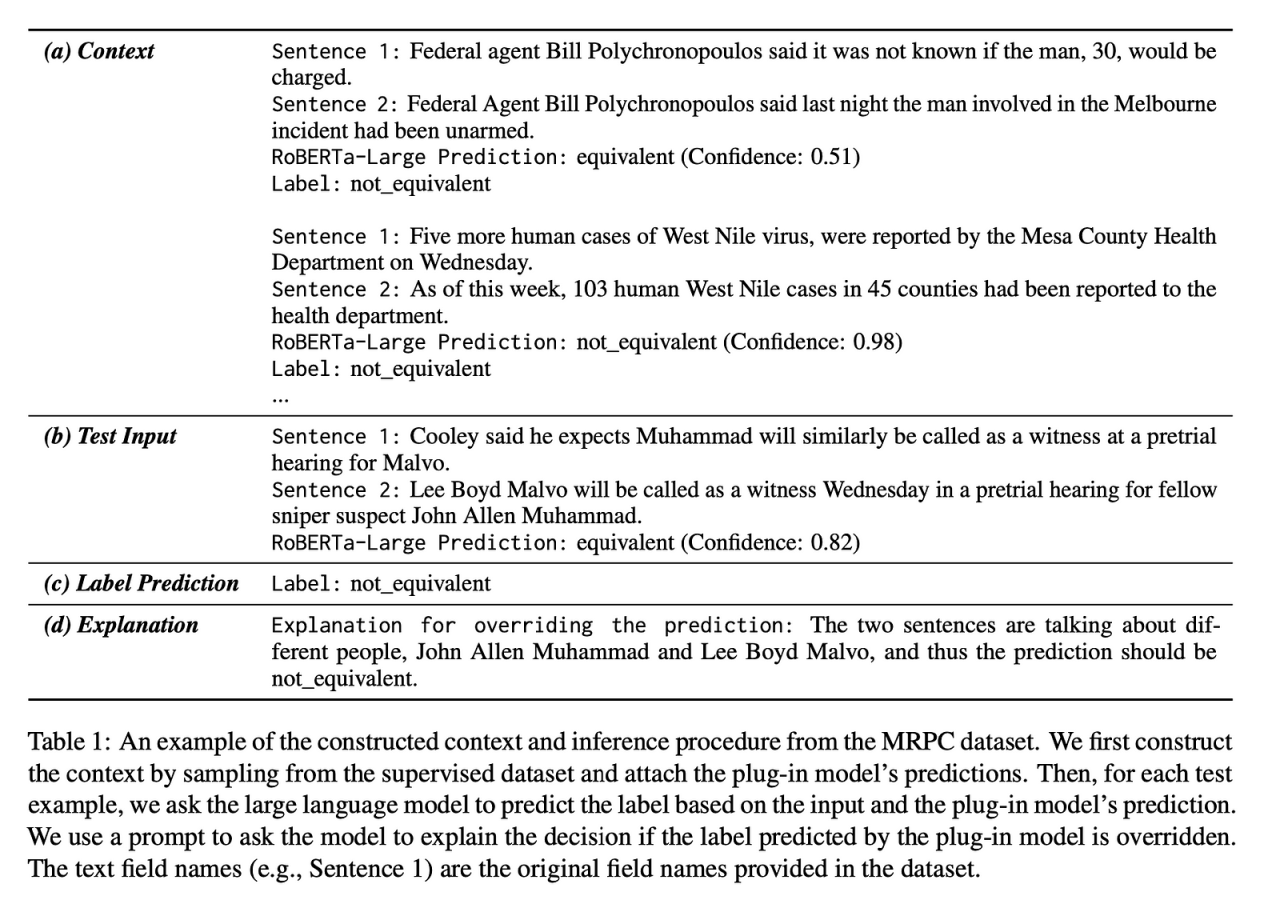
3. “插件”来拯救:SuperICL 方法简介
面对这些烦恼,研究者们提出了一个聪明的方案,可以称之为 SuperICL(超级上下文学习)。这个方法的核心思想很简单:让“通才教授”(LLM)在遇到专业问题时,去请教“特长生”(小模型插件)。具体的流程是这样的:首先,我们先用特定领域的专业知识,把“特长生”(小模型)训练好,比如用几千份客服对话记录,训练一个“金牌客服”小模型。接着,当用户提出一个问题时,先让这个“金牌客服”小模型处理一下,给出它认为最专业的初步答案。然后,把用户的问题和“金牌客服”的答案一起作为“专家级”的小纸条,递给“通才教授”(LLM)。最后,LLM 看到这张小纸条后,就能立刻领会意图,结合自己广博的知识,给出一个既专业又表达流畅的完美回答。通过这种方式,我们既利用了小模型在特定领域的深度,又利用了大模型的通用理解和生成能力,完美绕开了前面提到的三个烦恼。
4. “插件”模式的真实应用场景
这种“大带小”的模式听起来很酷,它已经在很多领域展现出巨大潜力。例如在定制化客服方面,通用聊天机器人装上一个“产品知识”小插件后,立刻就能变身为专业的电商客服,对自家商品了如指掌,回答问题又快又准。在医疗诊断辅助上,大模型负责与医生自然交互,而一个专门识别肿瘤特征的小模型插件,则为诊断提供关键的参考意见。它还可以用于法律合同分析,当律师将合同发给 AI 助手,助手背后的大模型负责总结和翻译,而一个“法律风险”小插件则能精准地标出合同中可能存在问题的条款。此外,对于一些小语种翻译,训练一个专门的小模型插件,也可以大大提升通用翻译软件在这些语言上的准确度和流畅度。
5. 当然,它也有局限
这种方法并非完美,也存在一些挑战。它很依赖“特长生”的水平,“插件”小模型的专业能力决定了整个系统的上限,如果插件本身不靠谱,大模型也无能为力。同时,训练成本依然存在,训练一个高质量的小模型插件,虽然比训练大模型便宜得多,但仍然需要数据和一定的计算资源。并且,它也并非万能,这种组合在很多理解和分析任务上效果显著,但在某些纯粹的创作或开放式对话任务上,可能优势就不那么明显了。
6. 结语
将小模型视为大语言模型的“插件”,是一种非常务实且高效的创新思路。它不再追求单一模型的“大而全”,而是通过构建一个优势互补的 AI 协作体系,让我们能够以更低的成本、更高的效率,打造出更专业、更懂我们需求的 AI 应用。

未来,我们可能会看到一个繁荣的“AI 插件”生态,就像手机应用商店一样,可以为自己的大模型按需挑选和安装各种能力,真正实现 AI 的个性化和普及化。