降低 Serverless 冷启动延迟的完整实践指南
开篇:为什么冷启动会让开发者抓狂?
Serverless 应用开发者经常面临一个性能瓶颈:用户首次访问应用时响应时间显著延长,但后续访问速度正常。这种现象被称为”冷启动”,是 Serverless 架构的固有特性。
冷启动发生在 Serverless 平台需要从零开始创建新的执行环境时。当没有可用的运行容器时,系统必须执行一系列耗时操作:创建新容器、拉取应用镜像、加载运行时环境、初始化应用代码。对于 AI 模型推理应用,这个过程更加复杂,需要额外下载数 GB 的模型权重文件。例如,一个典型的 Stable Diffusion 模型完整冷启动可能耗时 2-3 分钟。
冷启动对业务的影响是实际且可量化的。每增加 1 秒的响应延迟,用户转化率平均下降 7%,直接影响营收表现。延迟还会增加运营负担,包括额外的监控成本和客户投诉处理。在竞争激烈的市场环境中,响应速度慢的应用很难获得用户青睐。
本文将系统介绍 8 种经过生产环境验证的冷启动优化策略,涵盖从零成本的基础优化到企业级的高级解决方案,帮助开发者构建高性能的 Serverless 应用。
1. 快速决策流程图
在深入具体技术方案之前,我们先通过一个简单的决策流程来帮你快速定位最适合的优化策略:
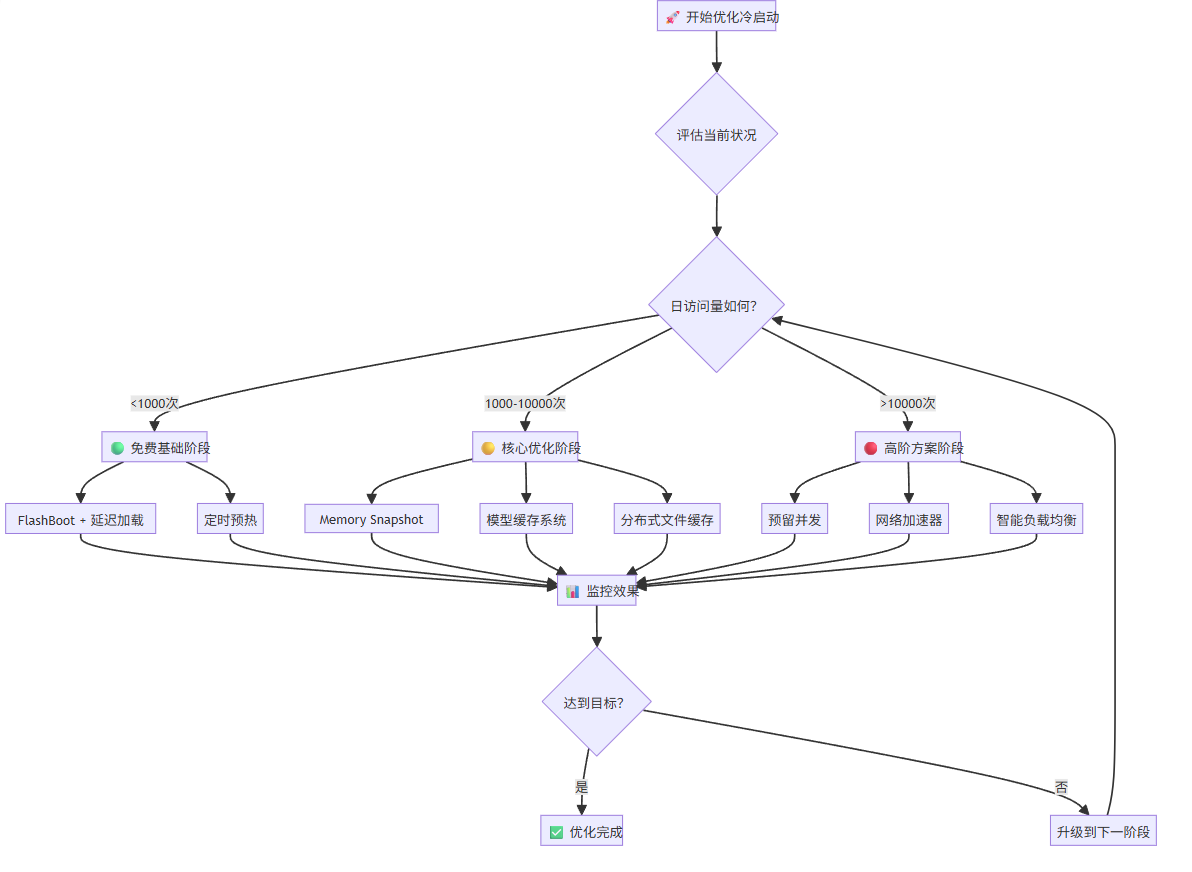
2. 免费基础阶段:零成本起步
2.1 预热型流量预测引擎:最经济的起点
当您刚开始优化冷启动问题时,预热型流量预测引擎是最理想的切入点。这项技术能:实时管理函数实例(容器)的部署、销毁和扩容活动。它完全免费且无需任何配置。这项技术通过机器学习预测用户访问模式,提前启动容器,能够将冷启动时间从原来的 10-15 秒降低到 500ms-1 秒,95% 的请求都能在 2.3 秒内完成。
它的工作原理是分析你的应用访问模式,当系统检测到某个端点可能即将收到请求时,会提前启动容器进行预热。
curl -X GET https://api.gongjiyun.io/v2/logs | grep "FlashBoot"需要注意的是,预热型流量预测引擎的效果高度依赖于你的流量模式。如果你的应用有规律的访问模式,比如工作日的上午流量较高,或者用户习惯在特定时间段使用,那么它的预测准确度会很高,效果显著。但如果是低频且随机的访问模式,效果就会比较有限。
2.2 延迟加载与智能缓存:专为 AI 应用设计
传统做法是在容器启动时就加载所有模型,这会拖慢启动速度。更聪明的做法是按需加载并缓存,这样既能减少初始容器启动时间,后续请求又能受益于缓存,还能避免为未使用的模型付费。
class LazyModelLoader: def __init__(self): self._model = None self._cache_path = "/tmp/model_cache"
def load_model(self): if self._model is None: if os.path.exists(self._cache_path): print("Loading from cache...") self._model = torch.load(self._cache_path) else: print("Downloading model...") self._model = download_and_load_model() torch.save(self._model, self._cache_path) return self._model在设计缓存策略时,优先使用 SSD 存储,因为访问速度比网络下载快 10 倍;实现 LRU 缓存策略来自动清理不常用模型;如果可能的话,考虑跨容器共享缓存(如使用 Network Volume),这样能让整个应用集群受益于同一份缓存。
2.3 定时预热:用”心跳”保持应用活跃
定时预热是一个成本极低但效果不错的策略,基本思路是通过定期发送请求来防止容器被销毁。你可以使用 cron 作业每 5 分钟调用一次健康检查端点,或者在代码中实现一个简单的调度器。
*/5 * * * * curl -X POST https://your-api.com/health-checkimport scheduleimport time
def keep_warm(): requests.get('https://your-endpoint.com/ping')
schedule.every(4).minutes.do(keep_warm)关键是要把间隔时间设为容器超时时间的 80%,使用轻量级的健康检查端点而不是完整的推理请求,并且要避免在低流量时段过度 ping 浪费资源。每天大约会产生 300-400 次轻量级请求,成本通常低于 1 美元,对于大多数应用来说都是可以接受的。
3. 核心优化阶段:平衡性能与成本
3.1 Memory Snapshot:内存快照
当基础优化无法满足你的性能需求时,Memory Snapshot 技术就成了一个很有吸引力的选择。这项技术就像游戏的存档功能,在容器完成预热后捕获完整内存状态,将内存快照保存到高速存储,当新容器启动时直接恢复内存状态,跳过所有初始化过程直接处理请求。
这种方式能带来显著的性能提升:传统冷启动需要 10-15 秒,使用快照后只需要 2-3 秒,性能提升达到 3-5 倍。实现起来也相对简单:
@app.function(memory_snapshot=True)def my_function(): # 预热逻辑 initialize_models()
# 标记快照点 create_memory_snapshot()
# 后续请求将从这里恢复 return handle_requests()不过这项技术也有一些限制需要考虑:只能快照 CPU 内存,GPU 显存需要特殊处理;快照文件通常比较大,需要高速网络传输;代码复杂度会增加,需要处理快照失效的情况。但对于大多数 AI 应用来说,这些限制都是可以接受的,特别是考虑到显著的性能提升。
3.2 模型缓存:工业级解决方案
如果你的应用已经有了一定的用户量,那么投资一个工业级的模型缓存系统就很有必要了。通过后台 Rust 线程预取权重文件,实现真正的后台并行下载,不阻塞容器启动。
model_cache: - repo_id: stabilityai/stable-diffusion-xl-base-1.0 revision: 462165984030d82259a11f4367a4eed129e94a7b use_volume: true volume_folder: sdxl-base allow_patterns: - "*.json" - "*.safetensors" ignore_patterns: - "*.bin" # 只缓存需要的格式这个系统的核心优势在于精确控制,你可以通过 allow_patterns 只缓存真正需要的文件格式,减少存储空间;支持私有仓库和多种存储源,包括 Hugging Face、S3、GCS 等;最重要的是支持真正的后台下载,让你可以在模型下载期间做其他初始化工作。
class Model: def load(self): # 可以在模型下载期间做其他初始化工作 random_vector = torch.randn(1000) # 5 秒初始化
# 这时候前 5-10GB 权重通常已经下载完成 self._lazy_data_resolver.block_until_download_complete()
# 现在可以安全地使用模型文件 self.model = torch.load("/app/model_cache/sdxl-base/model.safetensors")3.3 分布式文件系统缓存
当你的应用规模进一步扩大,多个实例需要共享模型权重时,分布式文件系统缓存就显得非常重要了。在区域级别缓存模型权重,多个 Pod 可以共享同一份缓存,热缓存的传输速度能达到 1GB/s 以上,还有 14 天自动垃圾回收机制来管理存储成本。
首次下载时以正常速度填充缓存,一旦缓存命中就能几乎瞬时完成;同一物理节点上的 Pod 还可以进行热缓存共享,进一步提升效率。
4.高阶方案阶段:追求极致性能
4.1 预留并发:最直接但最昂贵的解决方案
当你的应用已经有了稳定且可观的流量,用户体验要求极高时,预留并发就是最直接有效的解决方案。这就像在餐厅高峰期前提前准备好厨师,通过配置参数始终保持一定数量的”热”容器运行。
@app.function( min_containers=3, # 最少保持 3 个容器 buffer_containers=2, # 额外准备 2 个缓冲容器 scaledown_window=300 # 容器闲置 5 分钟后才销毁)def my_inference_function(): return process_request()预留并发能完全消除冷启动,响应时间接近 0,还支持动态调整来应对流量高峰。但代价也很明显:成本会显著增加,因为需要为闲置资源付费,而且需要准确预估流量模式。这种方案适合高频访问的生产服务,特别是用户体验要求极高的场景,比如实时对话的 AI 应用或者高频交易系统。
4.2 网络加速器:并行下载技术的威力
对于模型权重较大的应用,网络传输往往是冷启动的瓶颈。现代模型下载系统使用并行化字节范围下载技术,能大幅提升传输速度。这种技术的核心思想是将大文件分成多个小块,同时下载多个块,然后在本地重新组装。
这种技术能将单线程下载的 50-100 MB/s 提升到并行下载的 300-500 MB/s,在高带宽环境下甚至可达 1GB/s 以上。对于动辄几十 GB 的大模型来说,这种提升是非常显著的。
5. 完整优化路线
根据不同的业务场景和发展阶段,这里提供一个完整的渐进式优化路径。整个优化过程分为三个主要阶段:
免费基础阶段(0-1K QPS):这个阶段专注于零成本的优化方案,首先启用预热型流量预测引擎,然后实现延迟加载机制,接着配置定时预热来保持容器活跃,最后建立基础的监控体系来跟踪冷启动频率和响应时间。
核心优化阶段(1K-10K QPS):当应用有了一定流量后,开始投入资源进行深度优化。首先配置专业的模型缓存系统来加速权重加载,然后启用 Memory Snapshot 技术实现快速恢复,接着启用分布式缓存来支持多实例共享,最后优化网络下载策略提升传输效率。
高阶方案阶段(超过 10K QPS):针对高流量应用的极致性能优化。配置预留并发确保容器始终可用,部署智能负载均衡系统来优化请求分发,实现多区域部署来降低网络延迟,最终引入 AI 预测调度来主动预测和准备资源。
每个阶段都有明确的性能目标和成本预期,前一阶段的完成是进入下一阶段的基础。这种渐进式的方法能够确保投资回报率最大化,避免过度优化带来的资源浪费。
5.1 监控与调优的智能化
无论处于哪个优化阶段,持续的监控和调优都是必不可少的。建议建立一套完整的监控体系来跟踪关键指标,包括冷启动频率(冷启动次数除以总请求数)、平均冷启动时间、单次请求成本以及用户满意度指标(比如 95% 分位的响应时间是否达到目标 SLA)。
通过设置自动化的调优逻辑,系统能够根据实际运行情况自动调整优化策略。比如当冷启动频率超过 10% 时自动增加最小容器数量,当单次请求成本超过预算限制时启动缓存策略优化。这种智能化的调优机制既能保证用户体验又能有效控制成本。
5.2 成本效益的精确计算
在投入更高级的优化方案之前,精确计算成本效益是非常重要的。ROI 计算公式为:节省成本等于避免的用户流失价值减去优化投入成本。其中用户流失价值等于用户生命周期价值乘以流失率再乘以因延迟流失的用户数量,优化投入成本包括基础设施成本和开发时间成本。
以一个实际案例来说明计算方法:某 AI 图像生成应用月活跃用户 10,000,优化前冷启动率 30%、平均延迟 15 秒、月流失用户 500;优化后冷启动率 5%、平均延迟 2 秒、月流失用户 50。节省价值计算为 450 用户乘以 50 美元生命周期价值等于每月 22,500 美元,优化成本为每月 3,000 美元,ROI 达到 650%,这样的投资显然是非常值得的。
6. 优化建议与总结
冷启动优化不是一次性工程,而是需要持续关注的系统性工作。随着 AI 模型规模的不断增长,冷启动问题会变得更加突出,因此掌握有效的优化策略至关重要。对于刚开始的开发者,强烈建议从 FlashBoot 和延迟加载开始,这些技术完全免费且容易实现;当应用积累了稳定流量后,再考虑投入更多资源做深度优化;始终记住监控优先的原则,没有准确的数据就没有有效优化的基础;保持敏锐的成本意识,在用户体验和运营成本之间找到最佳平衡点;根据业务发展需要及时调整优化策略。
记住一个核心原则:最好的优化策略永远是最适合你当前业务发展阶段的策略。不要盲目追求最先进的技术,而要根据实际需求、用户规模和预算约束来选择合适的优化方案。通过渐进式的优化路径,你能够以最低的成本获得最大的性能提升,构建出真正快速响应的 Serverless 应用,为用户提供卓越的使用体验。