RAG 权威指南:从本地实现到生产级优化的全面实践
大型语言模型(LLM)的知识受限于其训练数据,这是一个众所周知的痛点。检索增强生成(RAG)技术应运而生,它如同一座桥梁,将这些强大的基础模型与企业所需的实时、动态信息连接起来,极大地拓展了 AI 的能力边界。RAG 将 LLM 从一个封闭的知识库,转变为一个能够提供准确、实时且紧密贴合上下文的动态工具。
本文将作为你的向导,带你深入探索 RAG 的世界。我们首先会从零开始,在本地环境中亲手构建一个完整的 RAG 应用,让你对核心流程有直观的理解。随后,我们将探讨一系列用于构建生产级解决方案的高级策略,涵盖从向量数据库选型到查询优化、再到结果重排等关键环节。
1. 理解 RAG 的核心:检索、增强与生成
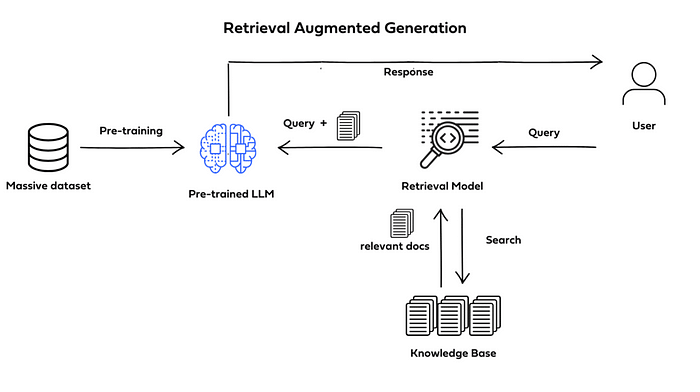
从“检索增强生成”这个名字,我们就能直观地理解其三大核心支柱:
-
检索 (Retrieval):当用户提出一个问题或查询时,RAG 系统并不会立即交给 LLM。相反,它会首先将用户输入作为检索指令,从一个外部的知识源(例如,你的文档、数据库或 API)中查找并获取最相关的信息片段。
-
增强 (Augmentation):系统会将上一步检索到的相关信息,与用户的原始问题进行整合,形成一个内容更丰富、上下文更明确的“增强版提示词”。
-
生成 (Generation):最后,这个增强后的提示词被送入 LLM。由于获得了额外的、高度相关的上下文信息,LLM 便能生成远比以往更准确、更具深度的回答。
这个流程确保了模型的输出不仅基于其内部的静态知识,更融合了外部的、最新的、特定的数据,从而有效减少了“幻觉”现象。
2. 从零到一:在本地构建你的第一个 RAG 应用
理论讲完了,让我们开始动手编码。这个实践环节将引导你在不依赖任何高级框架(如 LangChain 或 LlamaIndex)的情况下,一步步搭建一个可以运行的 RAG 系统。
2.1. 准备工作:设置环境
首先,我们需要安装一些必要的 Python 库。这些库将分别负责计算、PDF 读取、进度条显示以及与模型和嵌入相关的操作。
pip install torch PyMuPDF tqdm transformers sentence-transformers3.2. 知识源处理:解析与分块
RAG 的第一步是处理我们的知识源。这里以 PDF 文档为例,我们将它读取、清洗并切分成适合模型处理的小块(Chunks)。
import fitz # PyMuPDFfrom tqdm import tqdmfrom spacy.lang.en import Englishimport re
class PDF_Processor:
def __init__(self, pdf_path): self.pdf_path = pdf_path
@staticmethod def text_formatter(text: str) -> str: # 移除文本中的换行符等不必要的字符 cleaned_text = text.replace("\n", " ").strip() return cleaned_text
@staticmethod def split_list(input_list: list, slice_size: int) -> list[list[str]]: # 将列表按指定大小切片 return [ input_list[i : i + slice_size] for i in range(0, len(input_list), slice_size) ]
def _read_PDF(self) -> list[dict]: # 打开并逐页读取 PDF 内容 try: pdf_document = fitz.open(self.pdf_path) except fitz.FileDataError: print(f"错误:无法打开 PDF 文件 '{self.pdf_path}'.")
pages_and_texts = [] for page_number, page in tqdm( enumerate(pdf_document), total=len(pdf_document), desc="正在读取 PDF" ): text = page.get_text() text = self.text_formatter(text)
pages_and_texts.append( { "page_number": page_number, "text": text, } ) return pages_and_texts
def _split_sentence(self, pages_and_texts: list): # 使用 spacy 将文本分割成句子 nlp = English() nlp.add_pipe("sentencizer") for item in tqdm(pages_and_texts, desc="文本转句子"): item["sentences"] = list(nlp(item["text"]).sents) item["sentences"] = [str(sentence) for sentence in item["sentences"]] return pages_and_texts
def _chunk_sentence(self, pages_and_texts: list, chunk_size: int = 10): # 将句子列表按指定大小分块 for item in tqdm(pages_and_texts, desc="句子转分块"): item["sentence_chunks"] = self.split_list(item["sentences"], chunk_size) return pages_and_texts
def _pages_and_chunks(self, pages_and_texts: list): # 将分块重组成独立的字典对象 pages_and_chunks = [] for item in tqdm(pages_and_texts, desc="处理分块"): for sentence_chunk in item["sentence_chunks"]: chunk_dict = {} chunk_dict["page_number"] = item["page_number"]
# 合并句子块并清理格式 joined_sentence_chunk = "".join(sentence_chunk).replace(" ", " ").strip() joined_sentence_chunk = re.sub(r"\.([A-Z])", r". \1", joined_sentence_chunk)
chunk_dict["sentence_chunk"] = joined_sentence_chunk chunk_dict["chunk_token_count"] = len(joined_sentence_chunk) / 3 # 估算 token 数
if chunk_dict["chunk_token_count"] > 20: # 过滤掉过短的无效块 pages_and_chunks.append(chunk_dict)
return pages_and_chunks
def run(self): pages_and_texts = self._read_PDF() self._split_sentence(pages_and_texts) self._chunk_sentence(pages_and_texts) pages_and_chunks = self._pages_and_chunks(pages_and_texts) return pages_and_chunks这个类负责将输入的 PDF 转换成一系列带有元数据(如页码)的、有意义的文本块。有效的分块策略直接影响后续的检索质量。
2.3. 向量化:生成并存储嵌入
接下来,我们需要将这些文本块转换为机器能够理解的数学表示——即“嵌入”(Embeddings)。嵌入是捕捉文本语义含义的向量,它使得我们可以通过计算向量间的相似度来找到相关的文本。
from sentence_transformers import SentenceTransformerimport torchfrom tqdm import tqdmimport pandas as pd
class SaveEmbeddings:
def __init__(self, pdf_path, embedding_model="all-mpnet-base-v2"): self.device = "cuda" if torch.cuda.is_available() else "cpu" self.pdf_processor = PDF_Processor(pdf_path=pdf_path) self.pages_and_chunks = self.pdf_processor.run() self.embedding_model = SentenceTransformer( model_name_or_path=embedding_model, device=self.device )
def _generate_embeddings(self): # 逐块生成嵌入向量 for item in tqdm(self.pages_and_chunks, desc="正在生成嵌入"): item["embedding"] = self.embedding_model.encode(item["sentence_chunk"])
def _save_embeddings(self): # 将带有嵌入的数据保存到 CSV 文件,便于后续使用 data_frame = pd.DataFrame(self.pages_and_chunks) data_frame.to_csv("embeddings.csv", index=False)
def run(self): self._generate_embeddings() self._save_embeddings()这里我们使用了强大的 all-mpnet-base-v2 模型来生成嵌入,它能产生 768 维的向量。然后,我们将所有文本块及其对应的嵌入向量存储在一个 CSV 文件中。
2.4. 核心检索:实现语义搜索
有了嵌入向量,我们就可以构建检索器了。当用户查询时,我们同样将查询语句转换成嵌入向量,然后通过计算它与知识库中所有文本块向量的相似度(这里使用点积),来找出最相关的几个文本块。
import numpy as npimport pandas as pdimport torchfrom sentence_transformers import util, SentenceTransformer
class Semantic_search:
def __init__(self, embeddings_csv: str = "embeddings.csv"): self.device = "cuda" if torch.cuda.is_available() else "cpu" self.embeddings_df = pd.read_csv(embeddings_csv) self.embedding_model = SentenceTransformer( model_name_or_path="all-mpnet-base-v2", device=self.device ) self._process_embeddings() self.pages_and_chunks = self.embeddings_df.to_dict(orient="records") self.embeddings_tensor = self._convert_embeddings_to_tensor()
def _process_embeddings(self): # 从字符串格式恢复 numpy 数组 self.embeddings_df["embedding"] = self.embeddings_df["embedding"].apply( lambda x: np.fromstring(x.strip("[]"), sep=" ") )
def _convert_embeddings_to_tensor(self): return torch.tensor( np.array(self.embeddings_df["embedding"].tolist()), dtype=torch.float32 ).to(self.device)
def _retrieve_relevant_resources(self, query: str, n_resources_to_return: int = 5): query_embedding = self.embedding_model.encode(query, convert_to_tensor=True) # 计算点积分数 dot_scores = util.dot_score(query_embedding, self.embeddings_tensor)[0] # 获取分数最高的前 n 个结果 scores, indices = torch.topk(input=dot_scores, k=n_resources_to_return) return scores, indices
def run(self, query: str, n_resources_to_return: int = 5): relevant_chunks = [] scores, indices = self._retrieve_relevant_resources( query=query, n_resources_to_return=n_resources_to_return )
# 根据索引找到对应的文本块 for index in indices: sentence_chunk = self.pages_and_chunks[index]["sentence_chunk"] relevant_chunks.append(sentence_chunk)
return relevant_chunks注意:由于我们使用的 sentence-transformers 模型生成的嵌入是归一化的,因此使用点积等价于余弦相似度,并且计算效率更高。如果你的嵌入向量未经归一化,则应使用余弦相似度。
2.5. 增强环节:构建动态提示词
检索到的上下文不能直接丢给 LLM,我们需要通过一个精心设计的提示词模板,将上下文和原始查询优雅地结合起来。
class Create_prompt: def __init__(self): self.semantic_search = Semantic_search() self.base_prompt = """请根据以下提供的上下文信息,回答用户的问题。在回答问题前,请先在脑中思考并从上下文中提取相关段落,但不要在最终答案中展示思考过程。请确保你的回答尽可能详尽易懂。
上下文:{context}
用户问题:{query}
回答:"""
def _get_releveant_chunks(self, query: str): return self.semantic_search.run(query=query)
def _join_chunks(self, relevant_chunks: list): return "- " + "\n- ".join(item for item in relevant_chunks)
def run(self, query: str): relevant_chunks = self._get_releveant_chunks(query=query) context = self._join_chunks(relevant_chunks) prompt = self.base_prompt.format(context=context, query=query) return prompt2.6. 生成环节:集成 LLM
万事俱备,只欠 LLM。下面我们将加载一个本地语言模型(这里以 tiiuae/Falcon-1B-Instruct 为例,你可以换成其他兼容 transformers 库的模型),并让它根据我们生成的提示词进行回答。
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM
class LLM_Model: def __init__(self, model_id: str = "tiiuae/Falcon-1B-Instruct"): # 这是一个较小的模型,便于本地运行 self.device = "cuda" if torch.cuda.is_available() else "cpu" self.model_id = model_id self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=model_id) self.llm_model = AutoModelForCausalLM.from_pretrained( pretrained_model_name_or_path=model_id, torch_dtype=torch.bfloat16, # 使用 bfloat16 以节省显存 trust_remote_code=True, low_cpu_mem_usage=False, ).to(self.device)
if self.tokenizer.pad_token_id is None: self.tokenizer.pad_token_id = self.tokenizer.eos_token_id
def _get_model_inputs(self, base_prompt): # 使用模板构建模型输入 dialogue_template = [{"role": "user", "content": base_prompt}] input_data = self.tokenizer.apply_chat_template( conversation=dialogue_template, tokenize=True, add_generation_prompt=True, return_tensors="pt" ).to(self.device) return input_data
def run(self, base_prompt): input_data = self._get_model_inputs(base_prompt=base_prompt) output_ids = self.llm_model.generate( **input_data, max_new_tokens=256, # 控制生成文本的长度 do_sample=True, pad_token_id=self.tokenizer.pad_token_id, ) response = self.tokenizer.decode(output_ids[0], skip_special_tokens=True) # 清理模型输出,只返回助手的回答部分 response = response.split("assistant\n")[-1].strip() return response2.7. 组装完整流水线
最后,我们将所有组件串联起来,形成一个完整的、可执行的 RAG 应用。
import os
class Local_RAG: def __init__(self, pdf_path): self.pdf_path = pdf_path # 如果嵌入文件不存在,则创建它 if not os.path.exists("embeddings.csv"): print("未找到嵌入文件,正在生成...") self.save_embeddings = SaveEmbeddings(pdf_path=self.pdf_path) self.save_embeddings.run() print("嵌入文件生成完毕。")
self.create_prompt = Create_prompt() self.llm_model = LLM_Model()
def run(self, query): print("正在构建提示词...") base_prompt = self.create_prompt.run(query=query) print("正在生成结果...") response = self.llm_model.run(base_prompt=base_prompt) return response至此,你已经拥有了一个功能完备的本地 RAG 系统。尽管它很简单,但麻雀虽小五脏俱全,它清晰地展示了 RAG 的每一个核心步骤。
3. 迈向生产级:高级 RAG 实施策略
我们刚刚构建的本地 RAG 是一个绝佳的学习工具,但要将其投入生产环境,还需要考虑可扩展性、性能和准确性等一系列问题。下面,我们将探讨一些让 RAG 系统变得更强大的高级策略。
3.1. 向量数据库选型
我们之前用 CSV 文件存储向量,这对于小型项目来说足够了。但在生产环境中,你需要一个专门的向量数据库来高效处理海量数据和高并发查询。
选择向量数据库时,需要重点关注加载延迟、召回率和每秒查询数(QPS)。市面上的热门选项包括:
Pinecone:提供超快速的向量搜索,具备企业级合规性。
Milvus:云原生架构,在检索速度方面表现出色。
Weaviate:针对混合搜索进行了优化。
Chroma:对较小的数据集非常高效。
Elasticsearch:提供强大的混合检索和企业级的可扩展性。
你的选择应基于具体的应用场景。例如,对于需要即时响应的实时应用,Pinecone 或 Weaviate 是不错的选择;而对于大型文档的批处理,Milvus 则展现出卓越的可扩展性。
3.2. 优化嵌入模型
嵌入模型的质量直接决定了检索的天花板。你可以从 MTEB(大规模文本嵌入基准)排行榜入手,它对各种模型在不同领域的表现进行了全面比较。
选择时需要权衡维度大小与性能。像 OpenAI 的 text-embedding-ada-002(1536 维)这样的大型模型通常得分更高,但也需要更多存储和计算资源。而像 intfloat/e5-base-v2(768 维)这样更紧凑的模型,虽然基准分数稍低,但处理速度更快,存储成本也更低。
更重要的是,领域专业性。如果你的 RAG 系统专注于金融、医疗等特定领域,应优先选择在相关数据集上表现优异的模型。从一个较小的、特定领域的模型开始,通常比直接使用一个庞大的通用模型效果更好,因为后者可能在其训练数据上过拟合,导致在你的特定用例中表现不佳。此外,通过微调技术可以进一步提升嵌入模型在特定领域的性能。
3.3. 实施混合检索
单纯的向量搜索(密集检索)擅长理解语义,但有时会忽略关键词。而传统的关键词搜索(稀疏检索,如 BM25)则正好相反。混合检索结合了这两者的优点,能同时实现更高的精度和召回率。
一种实用的混合检索实现方式是,同时使用 BM25 和密集嵌入进行初步检索,然后使用一个重排器(Reranker)来融合两路结果,并给出最终的排序。重排器(如 BAAI/bge-reranker-base)是一个更强大的模型,它会同时评估查询和候选文档,从而更精确地判断相关性。
from some_reranker_library import Reranker
dense_candidates = vector_db.search(query, k=20)sparse_candidates = bm25_index.search(query, k=20)
all_candidates = list(set(dense_candidates + sparse_candidates))
reranker = Reranker(model="BAAI/bge-reranker-base")reranked_results = reranker.rerank(query, all_candidates, top_n=5)
final_context = "".join(reranked_results)4.4. 优化查询:学会“转变”思路
用户提出的问题可能很口语化,并不总是最适合直接进行向量检索的形式。查询转换技术可以在检索前对用户的原始问题进行改写或分解,从而提升检索的相关性。
查询重写 (Query Rewriting):使用一个 LLM 将口语化的查询转换成更结构化、更利于检索的格式。例如,将“那个有坚果和籽的能量棒里都有啥成分啊?”改写成更简洁的“坚果籽粒能量棒成分”。
查询分解 (Query Decomposition):当遇到复杂问题时(例如,“对比一下 A 和 B 两种方案的优缺点”),可以将其分解成多个更简单的子问题(“A 方案的优点是什么?”、“A 方案的缺点是什么?”等),分别进行检索,然后汇总答案。
生成假设性文档 (HyDE):一种有趣的技术,它先让 LLM 根据用户问题“幻想”出一个理想的答案文档,然后用这个虚构的文档的嵌入去检索真实文档。这种方法有时能更好地捕捉到查询背后的真实意图。
3.5. 增强结果:重排与过滤
在初步检索到一批文档后,我们还可以通过后处理来进一步提升最终送入 LLM 的上下文质量。
交叉编码器重排 (Cross-encoder Reranking):我们之前在混合检索中已经提到了重排器。交叉编码器(Cross-encoder)模型是性能最好的一类重排器,它会同时处理查询和文档,从而能捕捉到更细微的关联。由于计算成本较高,它非常适合用在召回之后的第二阶段,对少量候选文档进行精排序。
最大边际相关性 (MMR):有时检索出的文档虽然相关,但内容高度重复,这会浪费宝贵的上下文窗口。MMR 算法在选择文档时,会同时考虑其与查询的相关性以及与已选文档的差异性,从而在保证相关的前提下提升信息的多样性。
元数据过滤 (Metadata Filtering):在检索时或检索后,可以根据文档的元数据(如创建日期、作者、标签等)进行过滤,排除不符合条件的文档。
3.6. 超越文本:拥抱多模态与知识图谱
现实世界中的文档远不止纯文本,它们通常包含了丰富的图片、表格、甚至是数学公式。传统的 RAG 系统在这些非文本内容面前往往束手无策。为了应对这一挑战,多模态 RAG 的概念应运而生。
一个出色的开源实例是 RAG-Anything。它基于 LightRAG 框架构建,其核心创新在于能够统一处理和理解文本、图像、表格、公式等多种类型的内容,并将它们整合到一个统一的知识体系中。
与我们之前讨论的技术相比,RAG-Anything 引入了几个关键的升级:
-
知识图谱作为核心:它不再仅仅将文本块存为独立的向量,而是将从文档中识别出的各类信息(实体、关系、图片内容、表格数据等)构建成一个知识图谱。这种方式能更好地捕捉和利用信息之间的复杂关系,实现更深层次的理解和推理。
-
五阶段处理流程:为了精确处理复杂的文档,它设计了一个包含五个阶段的精密流水线:
解析阶段:识别并提取出文档中的不同内容类型。
模态处理阶段:调用专门的处理器(如图像、表格、公式处理器)对非文本内容进行理解。
上下文感知处理:这是其关键创新之一。在理解一个内容元素(如一张图片)时,系统会结合其周围的文本上下文,从而获得更精准的理解。
知识图谱构建:将所有处理后的结构化信息,整合并存入知识图谱。
检索与生成:当用户查询时,系统可以在知识图谱上进行更复杂的检索,并生成回答。
-
高度模块化与可扩展:系统设计了不同的模态处理器,并且易于扩展,可以应对未来可能出现的更多样的内容类型。
引入 RAG-Anything 这样的框架,意味着 RAG 系统从一个“文本问答”工具,进化成了一个能够深度理解和分析复杂、异构文档的“知识引擎”。
4. 总结
我们从零开始,亲手构建了一个本地 RAG 系统,深入了解了其内部的每一个环节。随后,我们探讨了从向量数据库、嵌入模型,到混合检索、查询转换和结果重排等一系列高级优化策略。
更进一步,通过了解像 RAG-Anything 这样的前沿项目,我们能看到 RAG 技术的未来发展方向:它正在超越纯文本的限制,迈向一个能够理解图像、表格、代码乃至更多模态的、由知识图谱驱动的全新阶段。
构建一个卓越的 RAG 系统是一个持续迭代和优化的过程。它不仅需要扎实的工程实现,更需要对数据、模型和用户需求的深刻理解。希望这篇指南能为你开启 RAG 的探索之旅提供一个坚实的起点,帮助你构建出更智能、更可靠的 AI 应用。