容器化部署 Whisper
本指南详细介绍了如何在共绩算力平台或本地环境部署 OpenAI Whisper 语音识别服务,并高效调用 API 实现语音转写与语言检测。
1. 部署步骤
Section titled “1. 部署步骤”我们在服务配置——预制镜像中提供了预构建的 Whisper 容器映像,旨在满足一般要求。您可以选择直接在共绩算力上运行这些容器以执行任务。或者,您还可以通过使用我们资源管理——镜像仓库所提供的免费 Docker 镜像仓库服务,来方便管理您自身的 Docker 镜像。
镜像仓库地址:https://console.suanli.cn/serverless/image 镜像仓库使用教程:https://www.gongjiyun.com/docs/y/NnNkwiWLkiD3m1kSgXDcRvsKnrJ/RKicwD7zQi39Lmkti9gc5PcunGb.html
1.1 访问共绩算力控制台
Section titled “1.1 访问共绩算力控制台”
1.2 进入服务列表后点击新增部署服务按钮
Section titled “1.2 进入服务列表后点击新增部署服务按钮”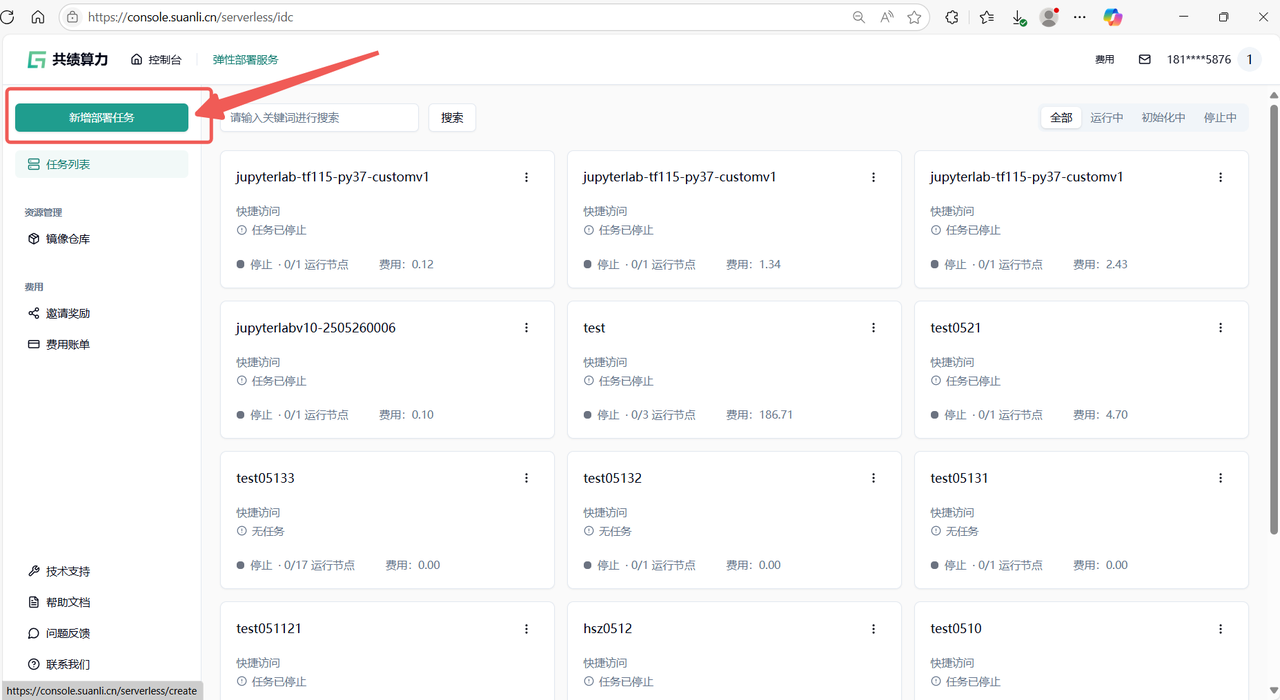
1.3 基于自身需要进行配置,参考配置为单卡 4090(初次使用进行调试)。
Section titled “1.3 基于自身需要进行配置,参考配置为单卡 4090(初次使用进行调试)。”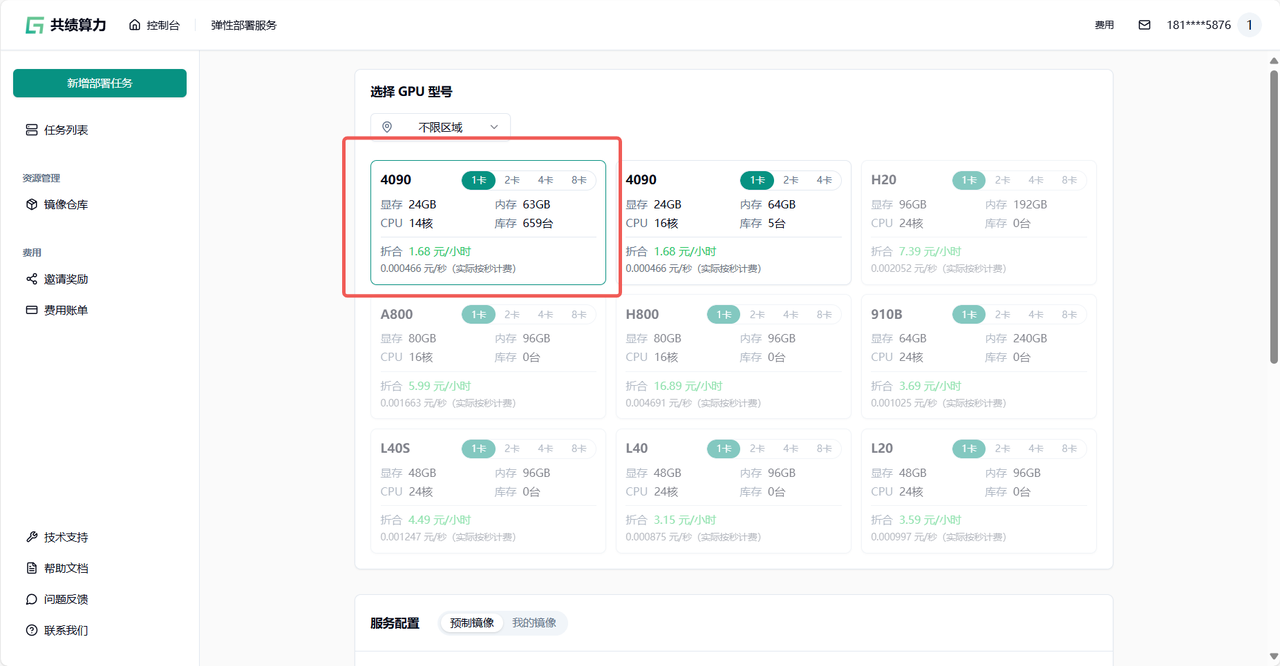
1.4 选择服务配置中的预制镜像 选择我们打包好的 Whisper 镜像快速开启服务
Section titled “1.4 选择服务配置中的预制镜像 选择我们打包好的 Whisper 镜像快速开启服务”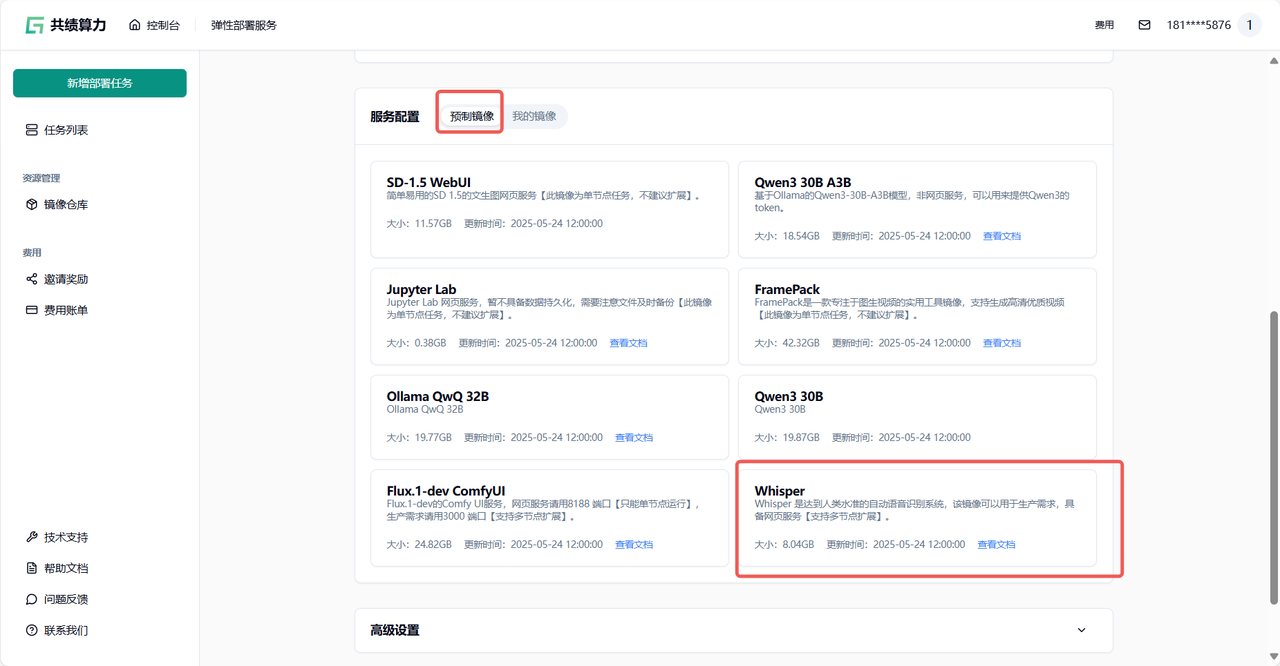
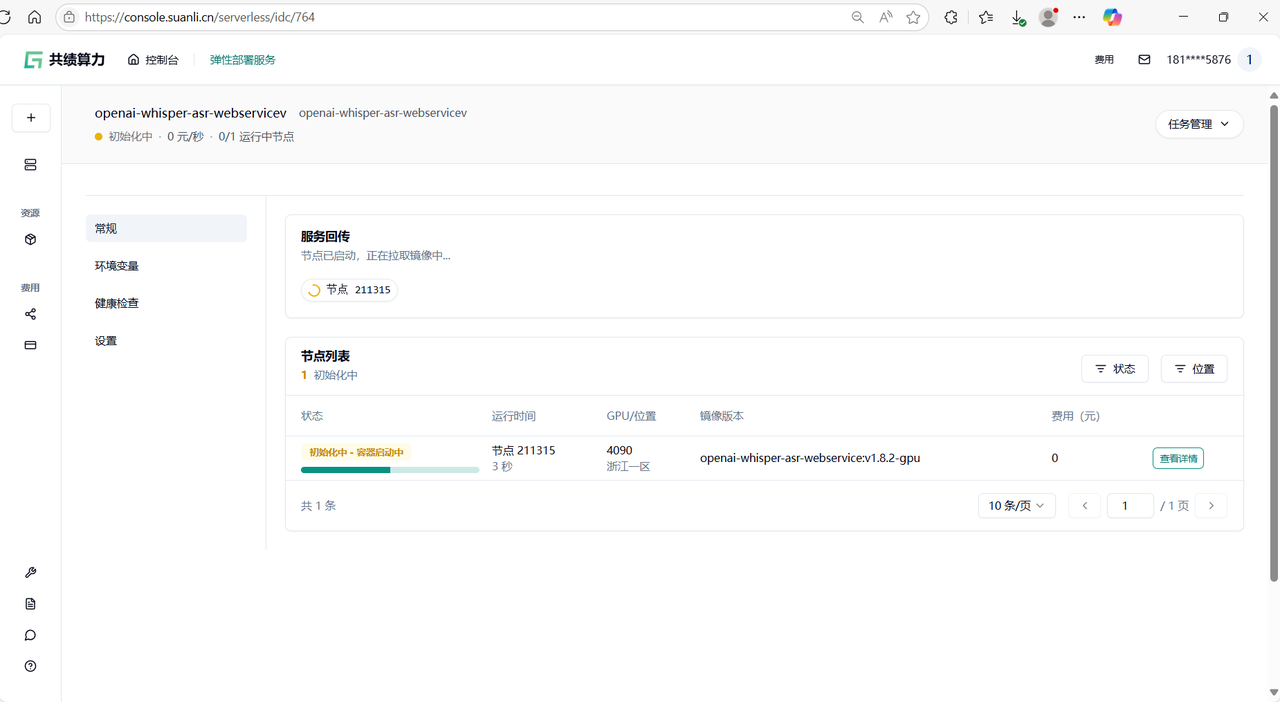
1.5 点击部署服务,耐心等待节点拉取镜像并启动 第一次访问会下载模型,所以需要稍等一会
Section titled “1.5 点击部署服务,耐心等待节点拉取镜像并启动 第一次访问会下载模型,所以需要稍等一会”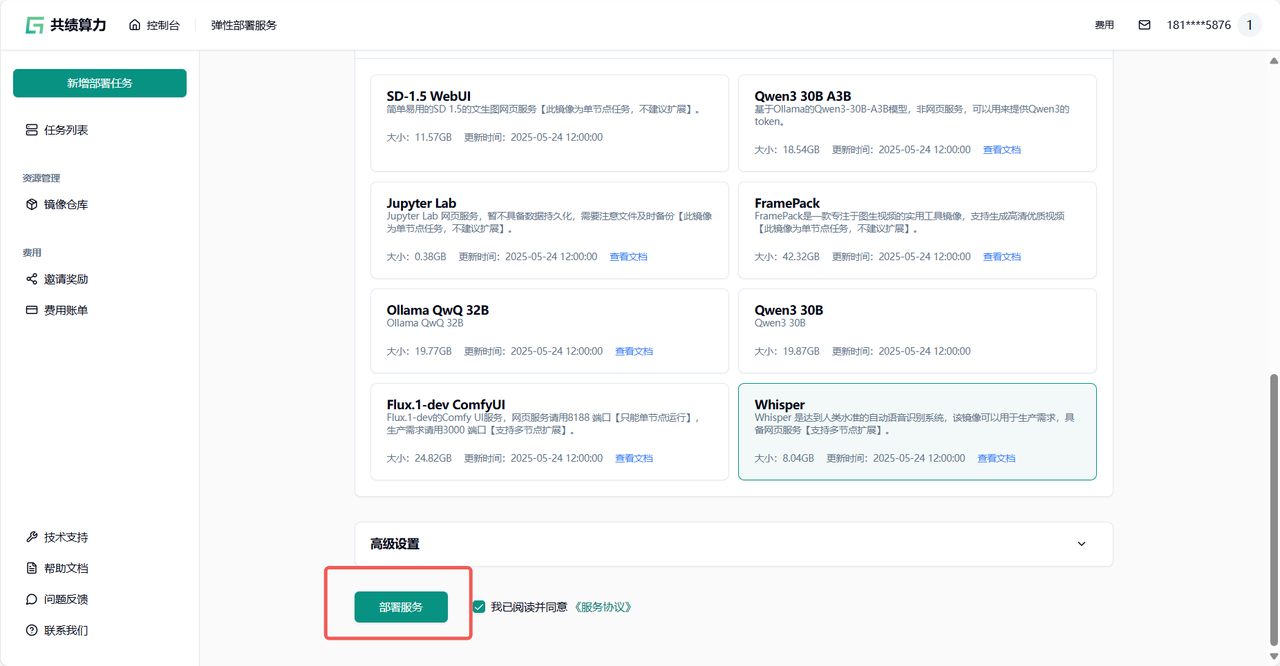
1.6 节点启动后,你所在“公开访问”中看到的内容可能如下:
Section titled “1.6 节点启动后,你所在“公开访问”中看到的内容可能如下:”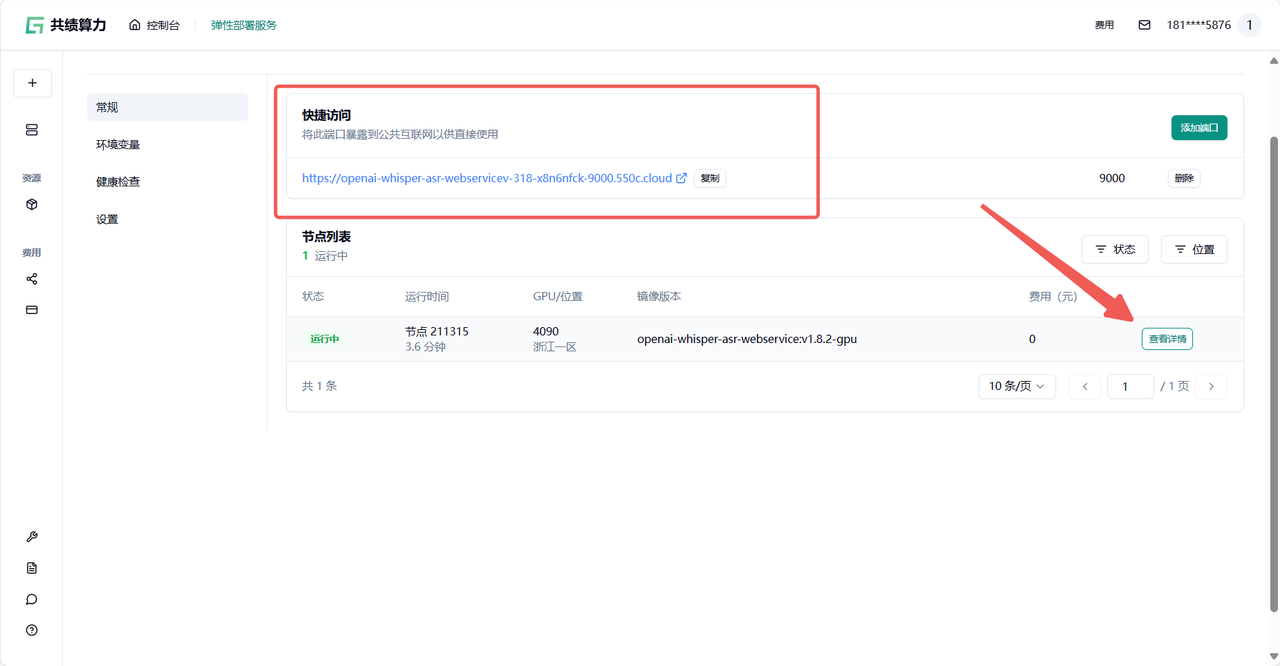
通过查看节点列表——查看详情 通过容器信息确定模型加载完成 即可正常进入服务
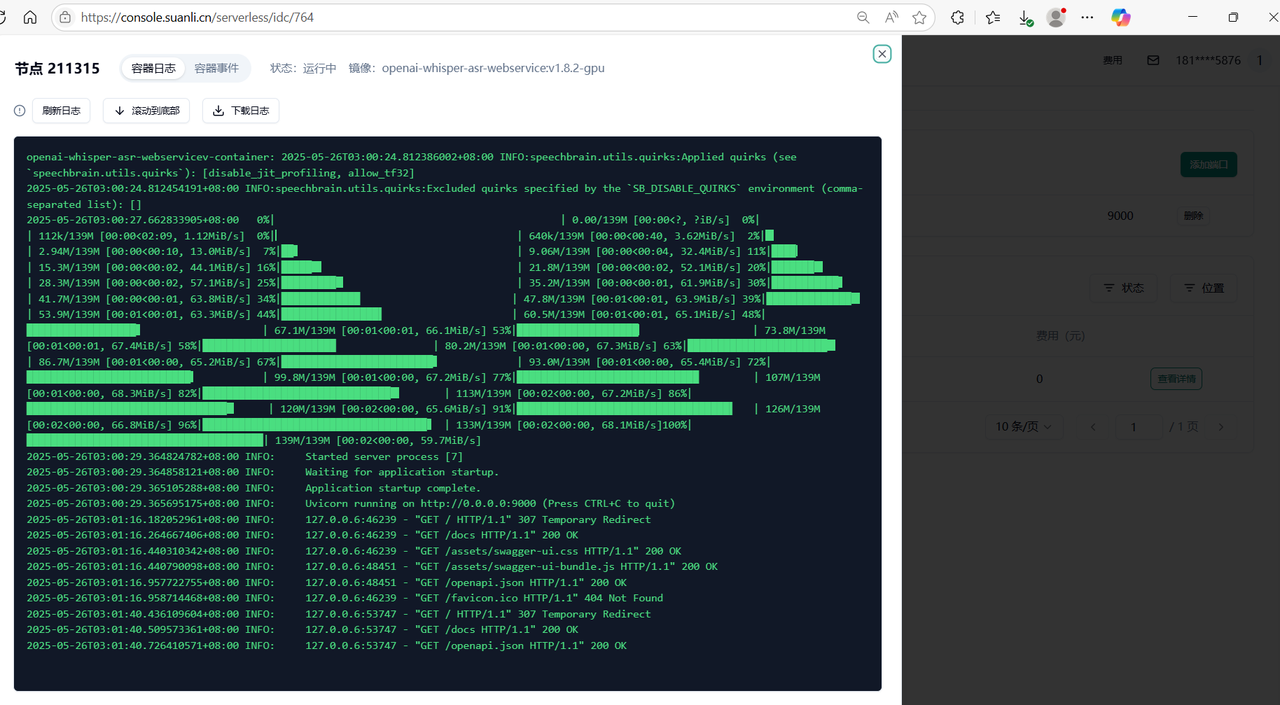
1.7 我们可以点击“9000”端口的链接,测试 whisper 部署情况,系统会自动分配一个可公网访问的域名,接下来我们即可自由地使用 whisper 的服务
Section titled “1.7 我们可以点击“9000”端口的链接,测试 whisper 部署情况,系统会自动分配一个可公网访问的域名,接下来我们即可自由地使用 whisper 的服务”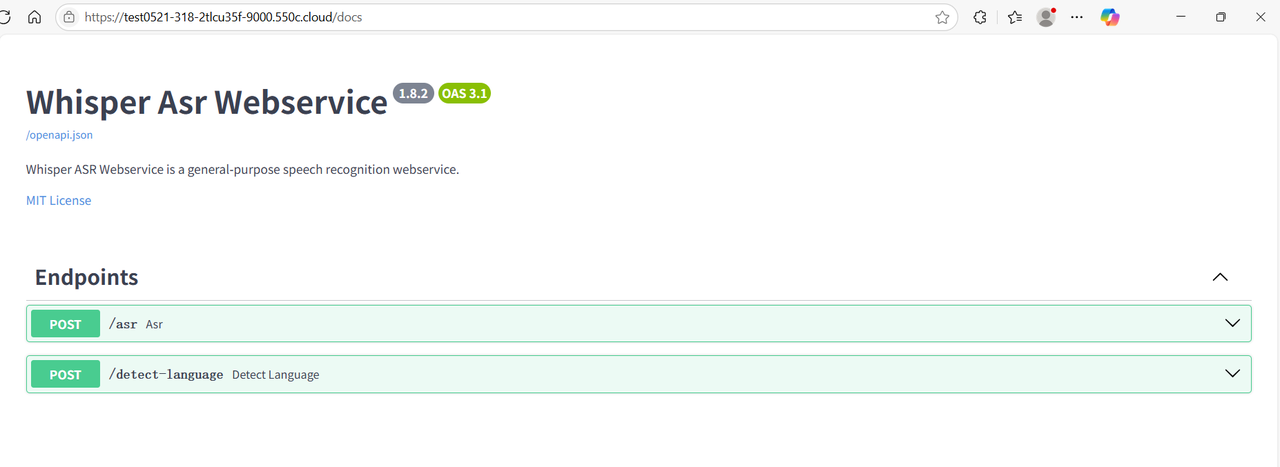
2. API 使用说明
Section titled “2. API 使用说明”Whisper 云端服务提供标准 HTTP API,支持多种音视频格式的语音识别与语言检测。
2.1 主要接口
Section titled “2.1 主要接口”/asr:语音识别接口,上传音频或视频文件,输出文字。
/detect-language:语言检测接口,上传音频或视频文件,输出语言。
2.1.1 语音识别接口(/asr)
Section titled “2.1.1 语音识别接口(/asr)”请求方式:POST
核心参数:
file:必填,上传音频/视频文件(.mp3, .wav, .mp4, .mov 等)
language:可选,指定音频语言(如 en、zh),留空自动检测
encode:可选,是否用 ffmpeg 预处理,推荐 true
task:可选,transcribe(转写,默认)/translate(翻译为英文)
output:可选,输出格式 txt/srt/json/vtt
请求示例:
curl -X POST "http://api.example.com/asr?language=zh&encode=true&output=json" \ -H "Content-Type: multipart/form-data" \ -F "file=@test.wav"返回示例:
{ "status": "success", "text": "这是识别出来的文本内容。"}2.1.2 语言检测接口(/detect-language)
Section titled “2.1.2 语言检测接口(/detect-language)”请求方式:POST
核心参数:
file:必填,上传音频/视频文件
encode:可选,推荐 true
请求示例:
curl -X POST "http://api.example.com/detect-language" \ -H "Content-Type: multipart/form-data" \ -F "file=@unknown_audio.wav"返回示例:
{ "status": "success", "language": "fr", "confidence": 0.92}3. Python 调用示例
Section titled “3. Python 调用示例”3.1 依赖安装
Section titled “3.1 依赖安装”pip install requests3.2 语音识别接口调用
Section titled “3.2 语音识别接口调用”场景一:会议录音转写为文本
Section titled “场景一:会议录音转写为文本”假设有一段中文会议录音 meeting.wav,希望自动转写为文本。
import requests----------------------请务必更换为您的服务地址----------------------ASR_API_URL = "http://api.example.com/asr"
def transcribe_audio(audio_file_path, language="zh", encode=True, task="transcribe", output="json"): """ 会议录音转写为文本,返回识别文本内容。 """ with open(audio_file_path, "rb") as f: files = {"file": f} params = {"encode": str(encode).lower(), "task": task, "output": output, "language": language} response = requests.post(ASR_API_URL, files=files, params=params) if response.status_code == 200: print("识别成功!\n返回:", response.json()) return response.json() else: print("识别失败,状态码:", response.status_code) print("错误信息:", response.text) return None
result = transcribe_audio("meeting.wav")场景二:英文音频自动检测语言并转写
Section titled “场景二:英文音频自动检测语言并转写”import requests----------------------请务必更换为您的服务地址----------------------ASR_API_URL = "http://api.example.com/asr"
def transcribe_auto_language(audio_file_path, encode=True, output="json"): """ 自动检测语言并转写英文音频。 """ with open(audio_file_path, "rb") as f: files = {"file": f} params = {"encode": str(encode).lower(), "output": output} response = requests.post(ASR_API_URL, files=files, params=params) if response.status_code == 200: print("识别成功!\n返回:", response.json()) return response.json() else: print("识别失败,状态码:", response.status_code) print("错误信息:", response.text) return None
result = transcribe_auto_language("english_audio.mp3")3.3 语言检测接口调用
Section titled “3.3 语言检测接口调用”场景三:上传音频自动检测语言
Section titled “场景三:上传音频自动检测语言”import requests----------------------请务必更换为您的服务地址----------------------DETECT_API_URL = "http://api.example.com/detect-language"
def detect_language(audio_file_path, encode=True): """ 检测音频文件的语言类型。 """ with open(audio_file_path, "rb") as f: files = {"file": f} params = {"encode": str(encode).lower()} response = requests.post(DETECT_API_URL, files=files, params=params) if response.status_code == 200: print("检测成功!\n返回:", response.json()) return response.json() else: print("检测失败,状态码:", response.status_code) print("错误信息:", response.text) return None
lang_info = detect_language("unknown_audio.wav")4. 网页服务与实际案例
Section titled “4. 网页服务与实际案例”4.1 英文音频转文字
Section titled “4.1 英文音频转文字”点击 /asr:语音识别接口 后点击页面右上角 Try it out 开始使用。
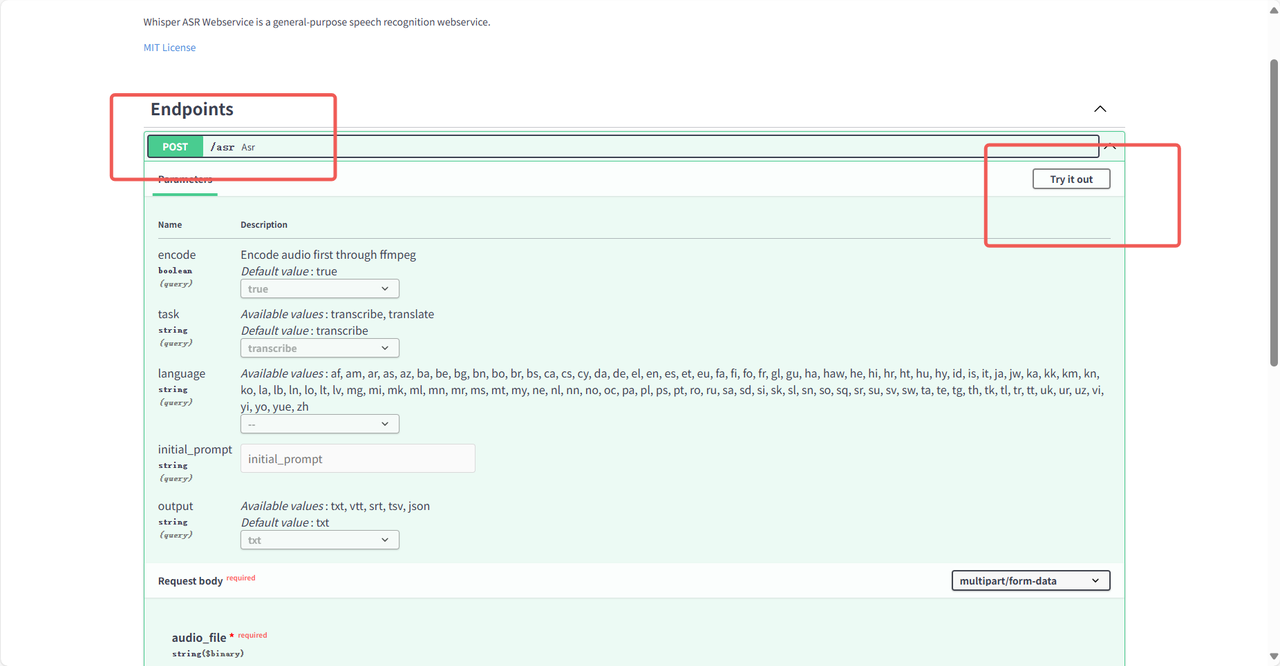
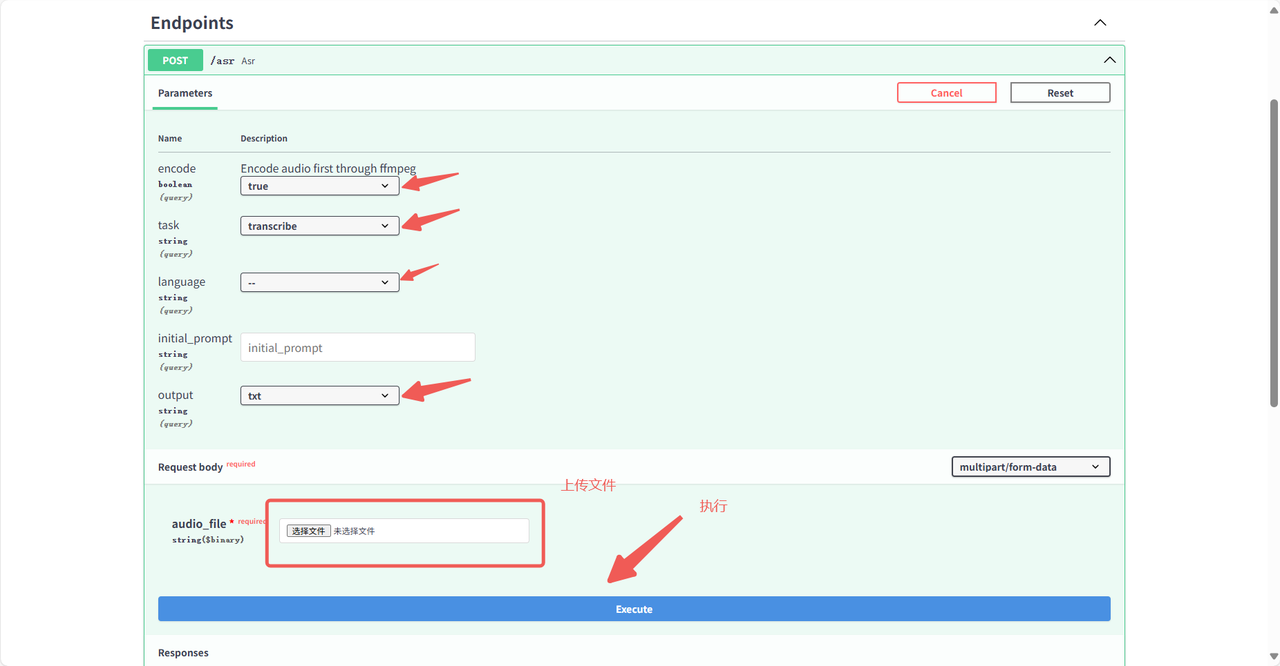
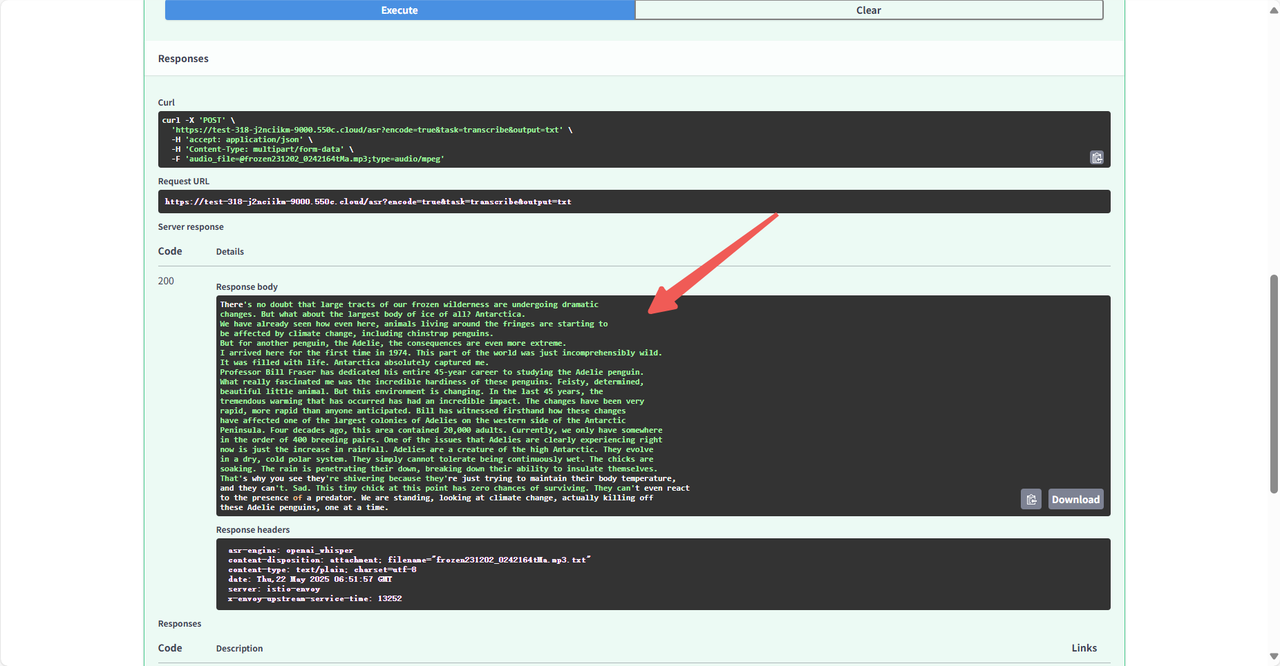
稍等片刻即可转换完成,在 response body 中可看到转换结果。
4.2 中文视频转文字
Section titled “4.2 中文视频转文字”同理,选择中文视频文件,参数 language 设为 zh,或 initial_prompt 指定简体中文。
4.3 语言检测
Section titled “4.3 语言检测”上传音频文件,系统自动检测语言类型。
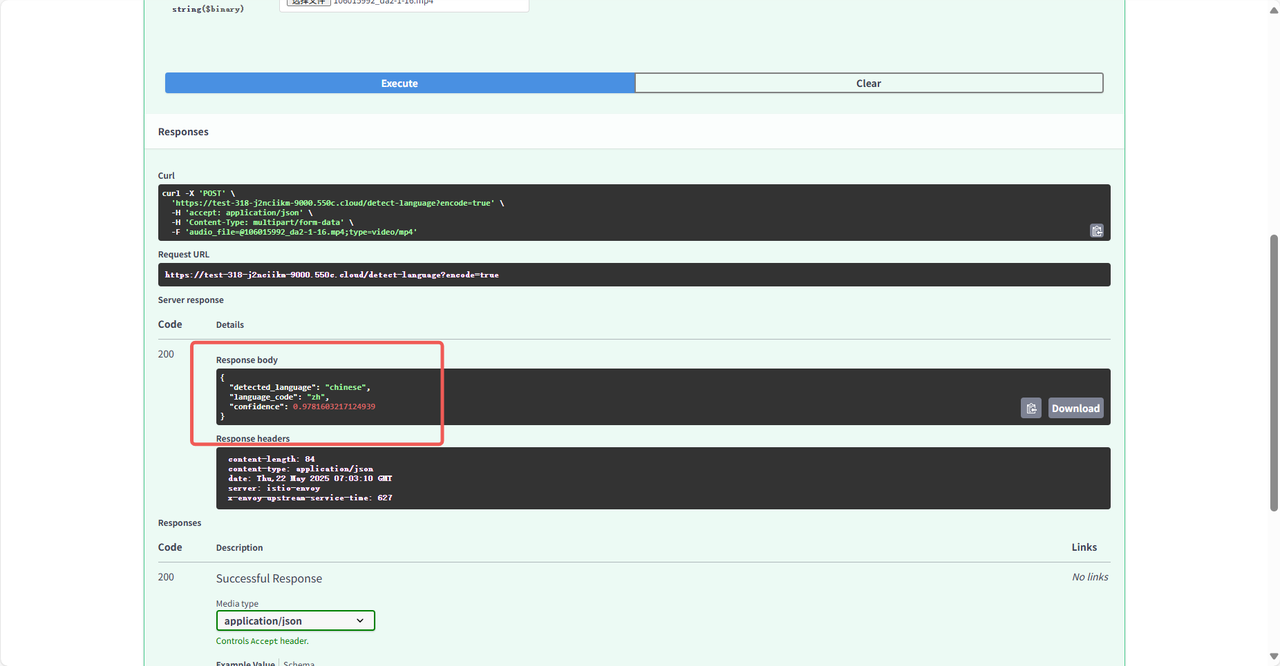
结果展示:
5. 常见问题与建议
Section titled “5. 常见问题与建议”共绩算力 Open API 使用文档:https://www.gongjiyun.com/docs/y/openapi/zx3iwhbv1i8sxdkeiapcprxhn8d/
音频格式要求:建议上传 wav、mp3、mp4 等常见格式,接口自动处理转码。
接口并发能力:云端服务支持高并发,适合批量转写和大规模业务集成。
错误处理:建议对接口返回的状态码和内容进行判断,便于异常追踪和日志记录。
安全性:如有敏感数据,建议通过 HTTPS 传输,避免明文泄露。
大文件处理:大于 50MB 建议用异步接口,或分片上传。
专业领域识别:可通过 initial_prompt 提升专业术语识别准确率。
附:Docker Hub 镜像本地快速部署
Section titled “附:Docker Hub 镜像本地快速部署”Whisper ASR Webservice 也可通过 Docker 方式在本地或云主机快速部署,支持 CPU 和 GPU。
- Docker Hub 镜像地址:https://hub.docker.com/r/onerahmet/openai-whisper-asr-webservice
CPU 版本启动示例
Section titled “CPU 版本启动示例”docker pull onerahmet/openai-whisper-asr-webservice:latestdocker run -d -p 9000:9000 \ -e ASR_MODEL=base \ -e ASR_ENGINE=openai_whisper \ onerahmet/openai-whisper-asr-webservice:latest环境变量说明
Section titled “环境变量说明”ASR_MODEL:要使用的 Whisper 模型(tiny、base、small、medium、large),默认 baseASR_ENGINE:ASR 引擎(openai_whisper,faster_whisper),默认 openai_whisperASR_MODEL_PATH:自定义模型文件存储/加载路径(可选)
每次启动容器时,都会下载 ASR 模型。为避免重复下载、加快启动速度,可将缓存目录挂载到本地:
docker run -d -p 9000:9000 \ -v $PWD/cache:/root/.cache \ onerahmet/openai-whisper-asr-webservice:latest使用持久缓存将阻止模型自动更新。
交互式 API 文档
Section titled “交互式 API 文档”- Swagger UI 可通过 http://localhost:9000/docs 访问